热门数据集


Kinetics-600
Kinetics-600 dataset
5140
17.7 MB
视频来源于YouTube,一共有600个类别,每个类别至少600个视频以上,每段视频持续10秒左右。
2020-10-31 (57月前)
免积分下载


印度新闻标题数据集
india-headlines-news-dataset
4311
226.84 MB
汇编了2001年至2017年印度“泰晤士报”发表的270万条新闻的标题。
2020-10-31 (57月前)
免积分下载

仇恨言语识别数据集
hate-speech-and-offensive-language
5317
3MB
ICWSM 2017论文“自动仇恨语音检测和无礼语言问题”的作者贡献。
2020-10-31 (57月前)
免积分下载

香港中文大学人脸素描数据集CUFSF
CUHK Face Sketch Database (CUFSF)
5315
香港中文大学人脸素描FERET数据库(CUFSF)用于人脸素描合成和人脸素描识别的研究。它包括来自FERET数据库的1194人。
2020-10-31 (57月前)
免积分下载

香港中文大学人脸素描数据集CUFS
CUHK Face Sketch Database (CUFS)
5985
它包括来自香港中文大学学生数据库的188张面孔,来自AR数据库的123张面孔、XM2VTS 数据库中的 295 个面总共有606张脸。
2020-10-31 (57月前)
免积分下载

CoPhIR 图像分类数据集
CoPhIR
4246
由 Flickr 中采集的约 1.06 亿个图像构成的数据集,主要用于图像分类,其中图像不仅包含位置、标题、标签、评论等图表本身的数据,还可从中提取出颜色模式、颜色布局、边缘直方图、均匀纹理等。
2020-10-31 (57月前)
免积分下载
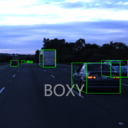
博世公司方形车辆检测数据集
THE BOXY VEHICLES DATASET
4698
1023.39GB
大型车辆检测数据集,包含近 200万辆带标注的车辆,用于训练和评估高速公路上自动驾驶汽车的物体检测方法。
2020-10-31 (57月前)
免积分下载

北京理工大学车辆车型识别数据集
BIT-Vehicle Dataset
11503
2.47G
北京理工大学车辆车型识别数据集,包含6个类别,总共9,850张车型图片;
2020-10-31 (57月前)
免积分下载

动物属性标记数据集
AwA2
6358
13GB
它由 50 个动物类的 37322 张图像组成,每个图像都有预提取的功能表示。这些类与奥舍森的经典类/属性矩阵 [3,4] 对齐,从而为每个类提供 85 个数值属性值。
2020-10-31 (57月前)
免积分下载

