
Kinetics-600
Kinetics-600 dataset
视频来源于YouTube,一共有600个类别,每个类别至少600个视频以上,每段视频持续10秒左右。
相关数据

Caltech-256 数据集
Caltech-256 是一个图像物体识别数据集,包含 30... 免积分下载
猫的图片数据集
超过9,000张带有面部标注特征的猫的图像数据集 免积分下载
CACD 跨年龄人脸识别和检索数据集
CACD 数据集是一个用于跨年龄的人脸识别和检索的大规模数据... 免积分下载数据介绍
视频来源于YouTube,一共有600个类别,每个类别至少600个视频以上,每段视频持续10秒左右。类别主要分为三大类:人与物互动,比如演奏乐器;人人互动,比如握手、拥抱;运动等。即person、person-person、person-object。
论文介绍:
下面这些介绍主要是参考于17年deepmind发的论文”The Kinetics Human Action Video Dataset”,当时还是400类的数据集。论文请见。
数据集主要关注人类行为,action类的列表包括:
单人行为,例如绘画,喝酒,大笑,抽拳;
人人行为,例如拥抱,亲吻,握手;
人物行为,例如打开礼物,修剪草坪,洗碗。
一些行动是比较细粒度的,需要时序推理来区分,例如,不同类型的游泳。其他动作类别需要强调区分对象,例如演奏不同类型的乐器。
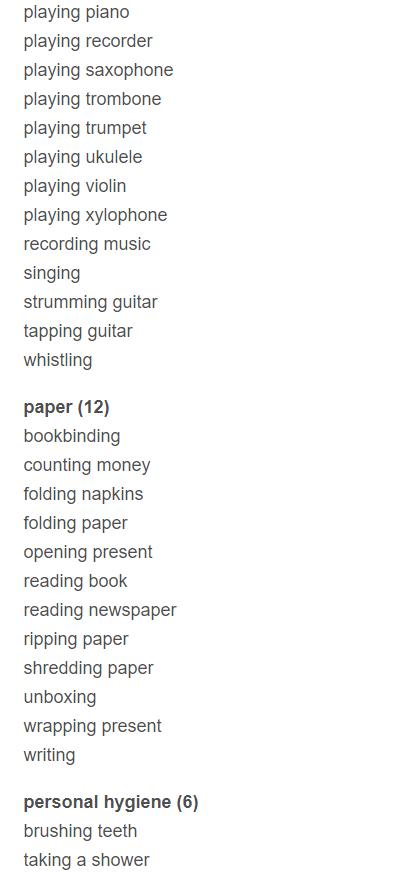
这些类别并没有严格的层级划分,但是还是有些的,类似父类子类关系,例如音乐类(打鼓、长号、小提琴、……),个人卫生类(刷牙、剪指甲、洗手、……),跳舞类(芭蕾、macarena、tap、……),烹饪(切割、煎、脱皮、……)等。
数据集有400个类别,每个动作都有400-1150个视频片段,每段视频的时长都在10秒左右。目前的版本有306245视频,分为三个部分,训练时每个类为250-1000个视频,验证时每个类50个视频,测试时每个类100个视频。
每个类都包含了一种行动。但是,一个特定的剪辑可以包含 几种动作。例如,开车”时“发短信”;“弹奏尤克里里”时“跳草裙舞”;“跳舞”时“刷牙”。这种情况下,这个视频只会标记一个标签,并不会同时存在于两个类种。因此,取top-5的准确率更为合适。
Benchmark
一共验证了三种处理行为识别的主流模型,分别是LSTM、two stream和3dcnn。
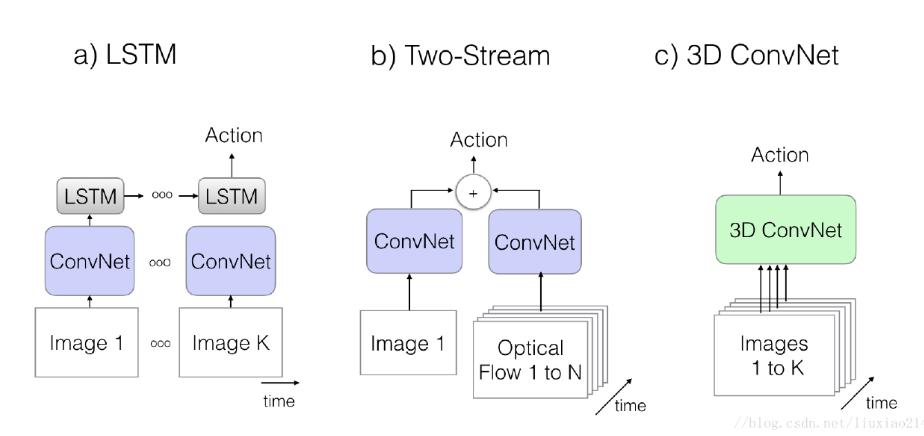
放上准确率,可以看出two-stream还是占据主导优势的。在kinetics数据集上,top-1是61.0,top-5是81.3。

分类结果分析
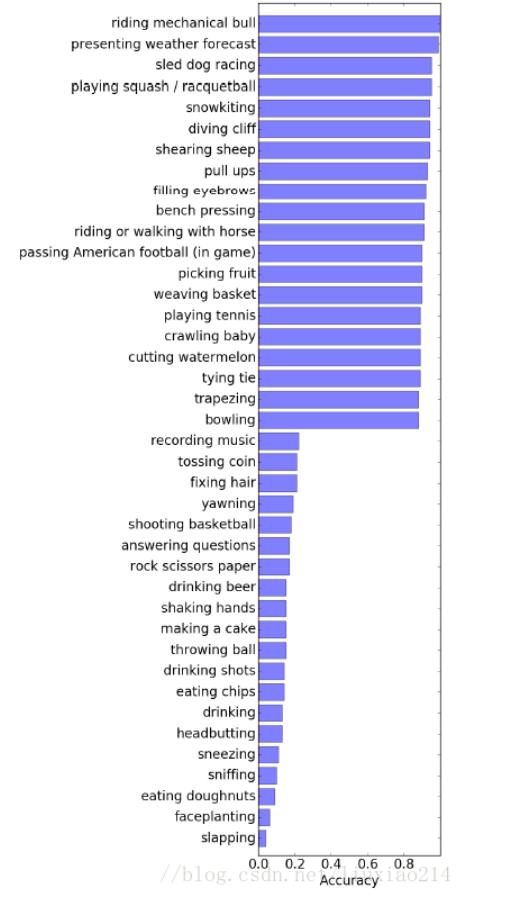
上图是那些类分的比较好,那些类分的比较差。
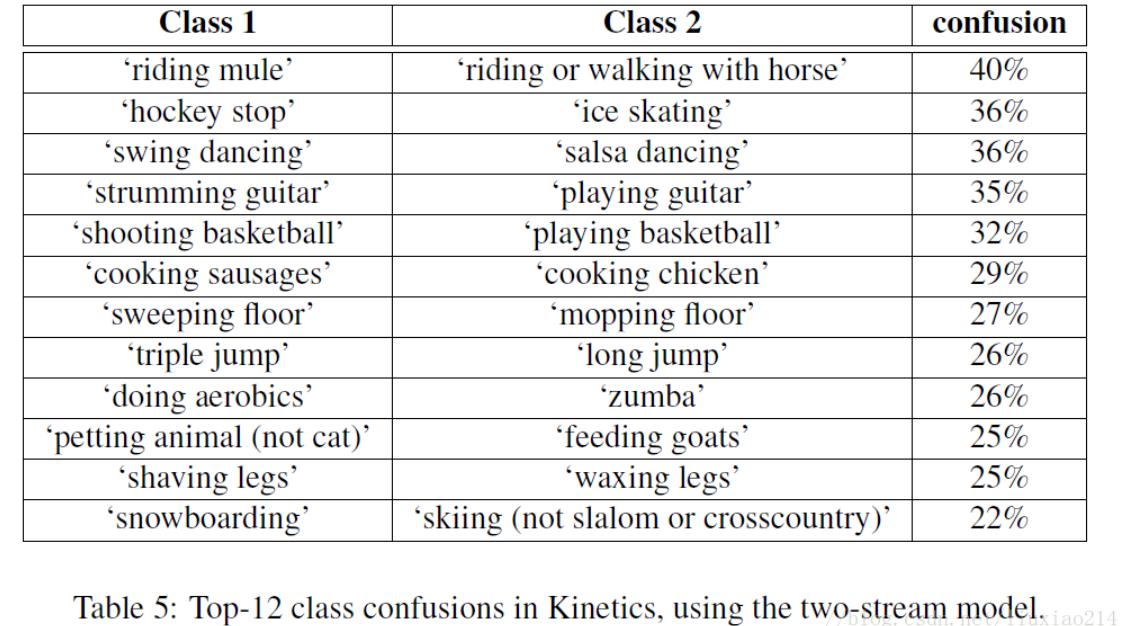
还有一点,由于很多动作比较细粒度,类别之间容易造成混淆,论文中也给出了最容易混淆的几个类别,比如,跳远和三级跳远,吃汉堡和吃甜甜圈。swing跳舞和跳萨尔萨舞等都会混淆。
如下图:
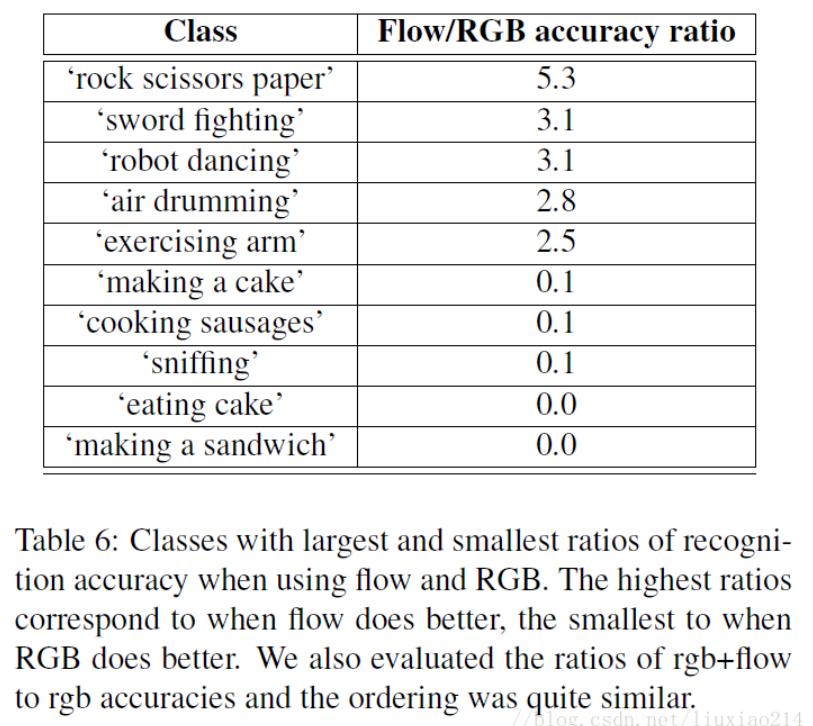
当然,由于使用two stream模型,光流模型和RGB模型可能对不同的动作有不同的准确度,对于这些特定类别,可以在融合时对光流和RGB设定不同的权重。
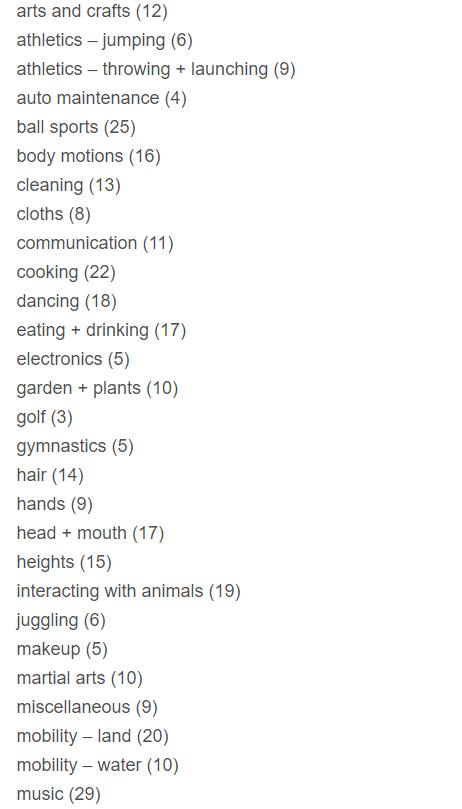
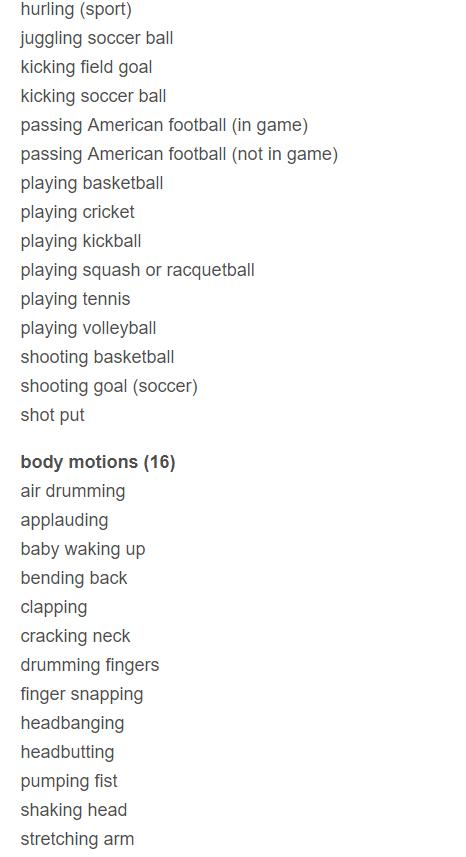
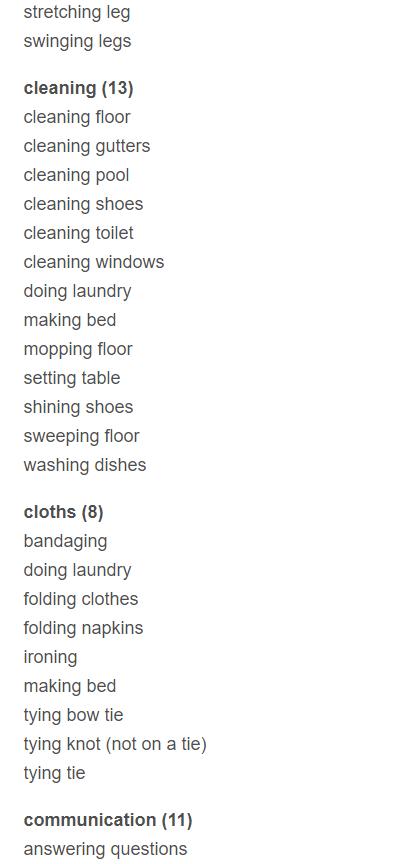
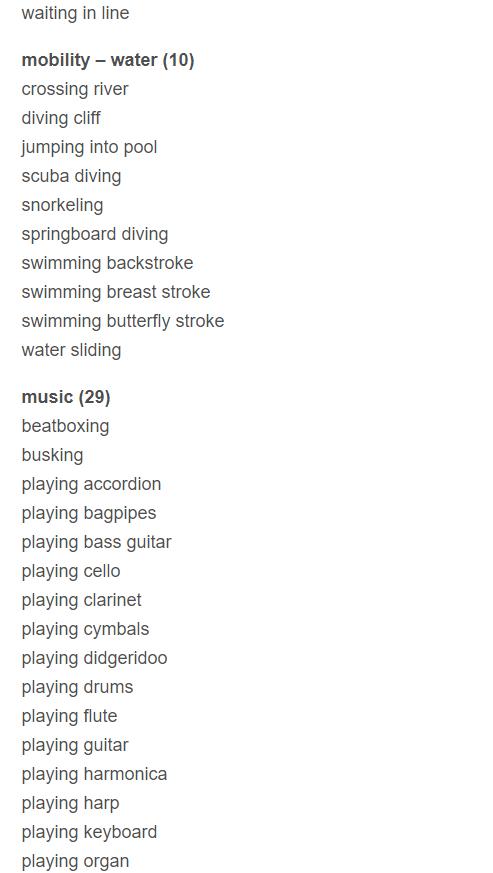
粒度划分
最后给出这些类别的一个粒度划分,可能有多个类别都会属于同一大类。即父类子类关系。
首先列出有哪些父类,然后再给出每个父类下的子类。
父类:
共38大类,每个类后面的数字代表有几个子类。














相关论文
[1] Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, Mustafa Suleyman, Andrew Zisserman, The Kinetics Human Action Video Dataset, 2017