
演员动作数据集
Actor-Action Dataset
演员动作数据集(A2D),其中包含43个演员和动作对的固定词汇,他们建立了一个多层条件随机场模型,并从一个视频中为每个超级体素分配一个来自演员动作产品空间的标签。
相关数据

微软图像裁剪数据集;
图像裁剪数据集包含由经验丰富的摄影师手动裁剪的1000张图像... 免积分下载
TWDNE 二次元头像数据集
TWDNE(This Waifu Does Not Exis... 免积分下载
宠物精灵图像数据集
从第1代到第7代的所有神奇宝贝的图像,以及它们的类型(主要和... 免积分下载数据介绍
我们从YouTube收集了一个新的数据集,其中包括3782个视频;
因此,这些视频是没有特定规则与特点的室外视频。
图 1 提供了视频的单帧示例。我们选择七类演员表演八个不同的动作。我们选择的演员包括铰接的演员,如成人,婴儿,鸟,猫和狗,以及刚性的演员,如球和汽车。这八个动作是爬山、爬行、吃饭、飞行、跳跃、滚动、跑步和行走。单个动作类可以由不同的参与者执行,但没有一个参与者可以执行所有八个操作。例如,我们不考虑在数据集中进行成人飞行或球跑。在某些情况下,我们推送了给定动作术语的语义,以维护一组小动作:例如,汽车运行意味着汽车在移动,跳球意味着球在弹跳。一个附加操作标签"无"添加到对列出的八个操作以外的操作以及后台未执行操作的扮演者以外的操作进行说明。因此,我们总共有43个有效的演员-动作元。

图1。我们新的演员动作数据集A2D中标记视频的蒙太奇。此蒙太奇中存在单个执行者动作实例以及多个执行者执行不同操作的示例。标签颜色从 HSV 颜色空间中挑选,以便相同的对象具有相同的色调(请参阅颜色图例图 2),其中黑色是背景。
要查询 YouTube 数据库,我们使用从演员动作元数生成的各种文本搜索。然后手动验证生成的视频以包含主执行组件-动作元组实例,然后进行时间调整以包含该执行组件-行动实例。修剪后的视频平均长度为 136 帧,最小帧数为 24 帧,最长为 332 帧。我们将数据集拆分为 3036 个训练视频和 746 个测试视频,在所有演员动作元组上均匀划分。图 2 显示了每个执行组件-动作元组的统计数据。A2D 中三分之一的视频有多个参与者执行不同的操作,这进一步使我们的数据集与大多数操作分类数据集区别。图 3 显示了具有多个参与者和操作的这些案例的确切计数。
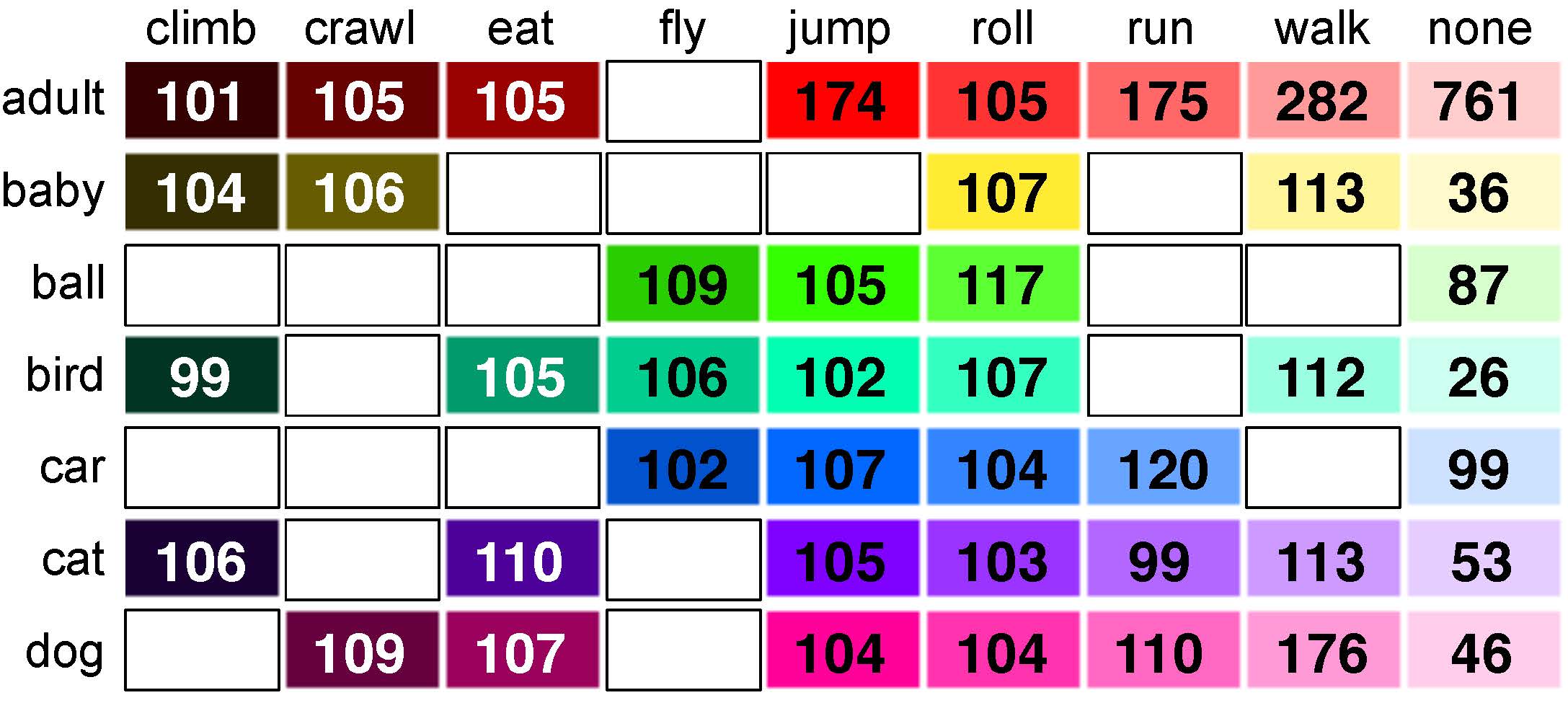
图2.新 A2D 数据集中标签计数的统计信息。我们显示数据集中出现给定 [参与者、操作] 标签的视频数量。空条目是未在数据集中的关节标签,因为它们无效(球不能吃)或供应不足,例如用于攀狗的情况。每个单元格中的背景颜色描述我们使用的颜色;我们为演员改变色调,为动作改变饱和度。
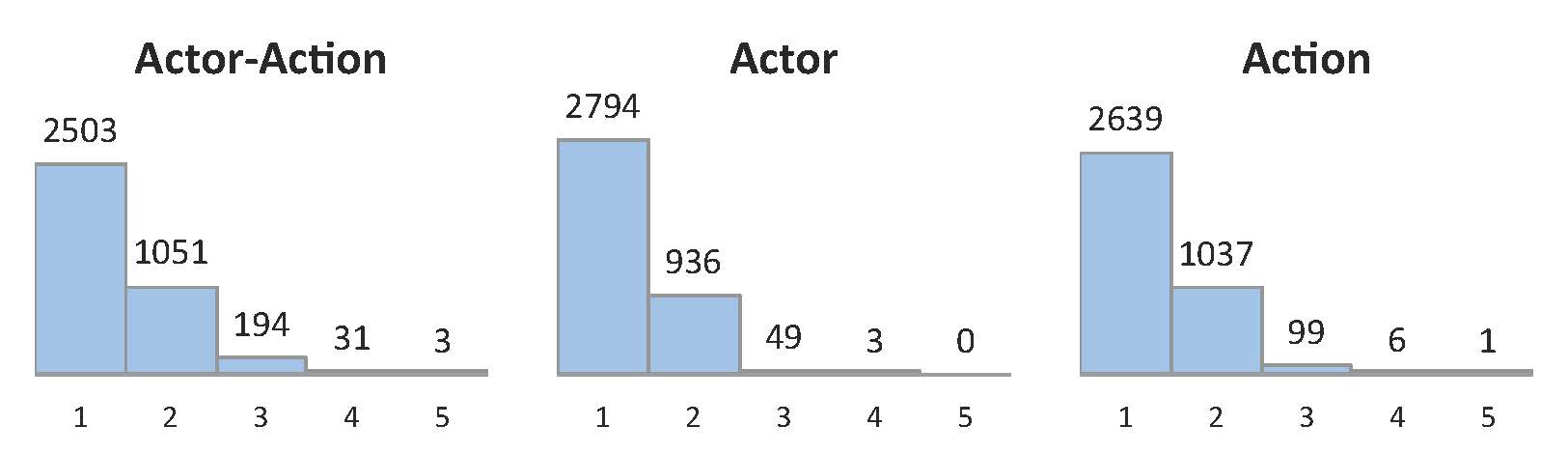
图3.A2D 中每个视频中联合演员-动作以及每个视频的单个演员和动作计数的直方图;大约三分之一的视频有一个以上的演员和/或动作。
为了支持考虑的更广泛的操作理解问题集,我们使用密集的像素级参与者和动作注释为数据集中的每个视频标记三到五帧(图 1 具有标记示例)。所选帧均匀分布于视频上。我们首先使用 LabelMe 工具箱从 MTurk 收集众包注释,然后手动筛选每个视频,以确保标签质量和标签的时间一致性。视频级标签直接从这些像素级标签中计算,用于识别任务。据我们所知,此数据集是第一个同时包含执行组件和动作像素级标签的视频数据集。
出版物:
| [1] | Y. Yan, C. Xu, D. Cai, and J. J. Corso. Weakly supervised actor-action segmentation via robust multi-task ranking. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2017. [ bib ] |
|---|---|
| [2] | C. Xu and J. J. Corso. Actor-action semantic segmentation with grouping-process models. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2016. [ bib | data ] |
| [3] | C. Xu, S.-H. Hsieh, C. Xiong, and J. J. Corso. Can humans fly? Action understanding with multiple classes of actors. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2015. [ bib | poster | data | .pdf ] |