musdb18曲目数据集
musdb18
musdb18是一个数据集,包括150首不同流派的全长音乐曲目(约10小时的持续时间),以及它们各自独立的鼓、低音、人声和其他词干。
相关数据
MS-微软语音语料库(印度语)
Microsoft Speech Corpus(印度语言)发... 免积分下载
VoxForge 语音库
VoxForge 创建的初衷是为免费和开源的语音识别引擎收集... 免积分下载
说话人深度识别数据集(VoxCeleb2)
VoxCeleb是一个视听数据集,由从上传到YouTube的... 免积分下载数据介绍
The sigsep musdb18 data set consists of a total of 150 full-track songs of different styles and includes both the stereo mixtures and the original sources, divided between a training subset and a test subset.
Its purpose is to serve as a reference database for the design and the evaluation of source separation algorithms. The objective of such signal processing methods is to estimate one or more sources from a set of mixtures, e.g. for karaoke applications. It has been used as the official dataset in the professionally-produced music recordings task for SiSEC 2018, which is the international campaign for the evaluation of source separation algorithms.
musdb18 contains two folders, a folder with a training set: “train”, composed of 100 songs, and a folder with a test set: “test”, composed of 50 songs. Supervised approaches should be trained on the training set and tested on both sets.
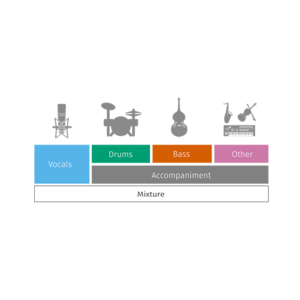
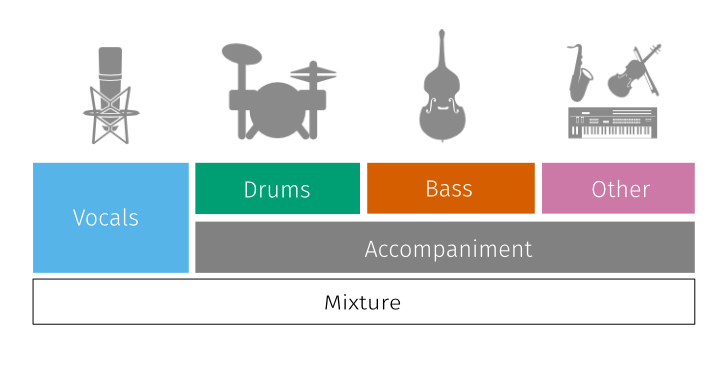
All files from the musdb18 dataset are encoded in the Native Instruments stems format (.mp4). It is a multitrack format composed of 5 stereo streams, each one encoded in AAC @256kbps. These signals correspond to:
- 0 - The mixture,
- 1 - The drums,
- 2 - The bass,
- 3 - The rest of the accompaniment,
- 4 - The vocals.
For each file, the mixture correspond to the sum of all the signals. All signals are stereophonic and encoded at 44.1kHz.
As the MUSDB18 is encoded as STEMS, it relies on ffmpeg to read the multi-stream files. We provide a python wrapper called stempeg that allows to easily parse the dataset and decode the stem tracks on-the-fly.
If you use the MUSDB dataset for your research - Cite the MUSDB18 Dataset
@misc{MUSDB18,
author = {Rafii, Zafar and
Liutkus, Antoine and
Fabian-Robert St{\"o}ter and
Mimilakis, Stylianos Ioannis and
Bittner, Rachel},
title = {The {MUSDB18} corpus for music separation},
month = dec,
year = 2017,
doi = {10.5281/zenodo.1117372},
url = {https://doi.org/10.5281/zenodo.1117372}
}
If compare your results with SiSEC 2018 Participants - Cite the SiSEC 2018 LVA/ICA Paper
@inproceedings{SiSEC18,
author="St{\"o}ter, Fabian-Robert and Liutkus, Antoine and Ito, Nobutaka",
title="The 2018 Signal Separation Evaluation Campaign",
booktitle="Latent Variable Analysis and Signal Separation:
14th International Conference, LVA/ICA 2018, Surrey, UK",
year="2018",
pages="293--305"
}