
4288
来自必应查询的经过训练的双词嵌入语料
Dual Word Embeddings Trained on Bing Queries
bing
必应
文本语料
文本数据集
双词嵌入
该数据仅出于研究目的而发布。DESM词嵌入数据集可能包含一些人可能会认为令人反感,不雅或其他令人反感的术语。Microsoft尚未审查或修改数据集的内容。
免积分下载
数据集市
2020年06月24日
10.3GB
相关数据

Twitter情感分析训练语料库
该情感分析数据集 包含1,578,627条分类推文,每行标记... 免积分下载
多领域情感评论文本数据集
多领域情感数据集包含从Amazon.com获取的部分产品评论... 免积分下载
Euler图学习开源数据集
Euler图学习平台自研算法对应的开源图数据与样本数据 免积分下载数据介绍
该双嵌入空间模型(DESM)是一个信息检索模型使用两个词的嵌入,一个查询词和一个文档的话。
它考虑了每个查询词向量与所有文档词向量之间的向量相似度。
信息检索的主要挑战是对文档的有关性进行建模。传统方法使用词频,出现更多查询词表示文档更可能与该词有关。DESM使用多个文档词作为每个查询词的关联性证据。例如,对于查询词“ Albuquerque”,以下两个文本段落根据词频无法区分,每个出现一次。我们的方法考虑了诸如“人口”和“都市”之类的相关术语的存在,这证明了段落(a)与阿尔伯克基有关,而段落(b)仅提及阿尔伯克基。

在这里,我们使用众所周知的工具word2vec生成双重嵌入。在大多数word2vec研究中,单词嵌入仅来自模型的输入矩阵(IN)。在本文中,我们还使用输出矩阵(OUT)嵌入。在下表中,“耶鲁”的IN向量与“哈佛”的IN向量(IN-IN)接近,但在OUT空间中,其最接近的邻居是“教师”(IN-OUT)。单一嵌入方法(IN-IN和OUT-OUT)倾向于将相同类型的词归为一组(典型),而双重嵌入方法(IN-OUT)将在训练数据中一起出现的词归为一组(局部)。
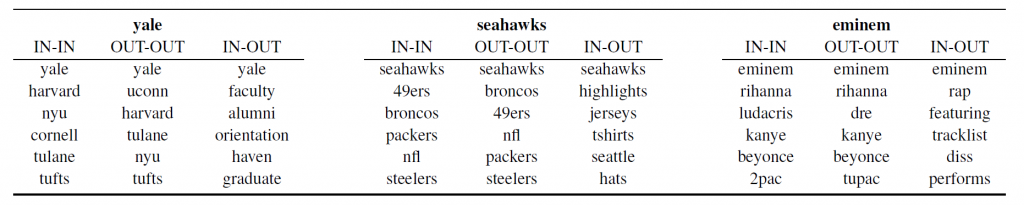
使用双重嵌入执行全对比较的DESM方法在信息检索测试平台上产生了积极的结果。
还没有任何文件记录.