
微软生成神经视觉艺术家数据集
GeNeVA_datasets
条件文本到图像生成,现有研究主要侧重于在一个步骤中从可用的调理信息生成单个图像。一步一代以外的实际扩展是一个系统,该系统以迭代方式生成图像,但以持续的语言输入或反馈为条件。
相关数据

Caltech-256 数据集
Caltech-256 是一个图像物体识别数据集,包含 30... 免积分下载
猫的图片数据集
超过9,000张带有面部标注特征的猫的图像数据集 免积分下载
CACD 跨年龄人脸识别和检索数据集
CACD 数据集是一个用于跨年龄的人脸识别和检索的大规模数据... 免积分下载数据介绍
GeNeVA 任务包括一个叙述者,为绘画者提供一系列语言指令,以达到图像生成的最终目标。
叙述者能够通过生成图像的视觉反馈来衡量进度。这是一项具有挑战性的任务,因为绘画者需要学习如何将复杂的语言指令映射到画布上的真实对象,不仅要维护对象属性,还要维护对象之间的关系(例如,相对位置)。绘画者还需要以与以前的图像和说明一致的方式修改现有的图形,因此需要记住以前的说明。所有这些都涉及到理解场景中对象之间的复杂关系,以及如何在图像中以与给出的所有指令一致的方式表达这些关系。

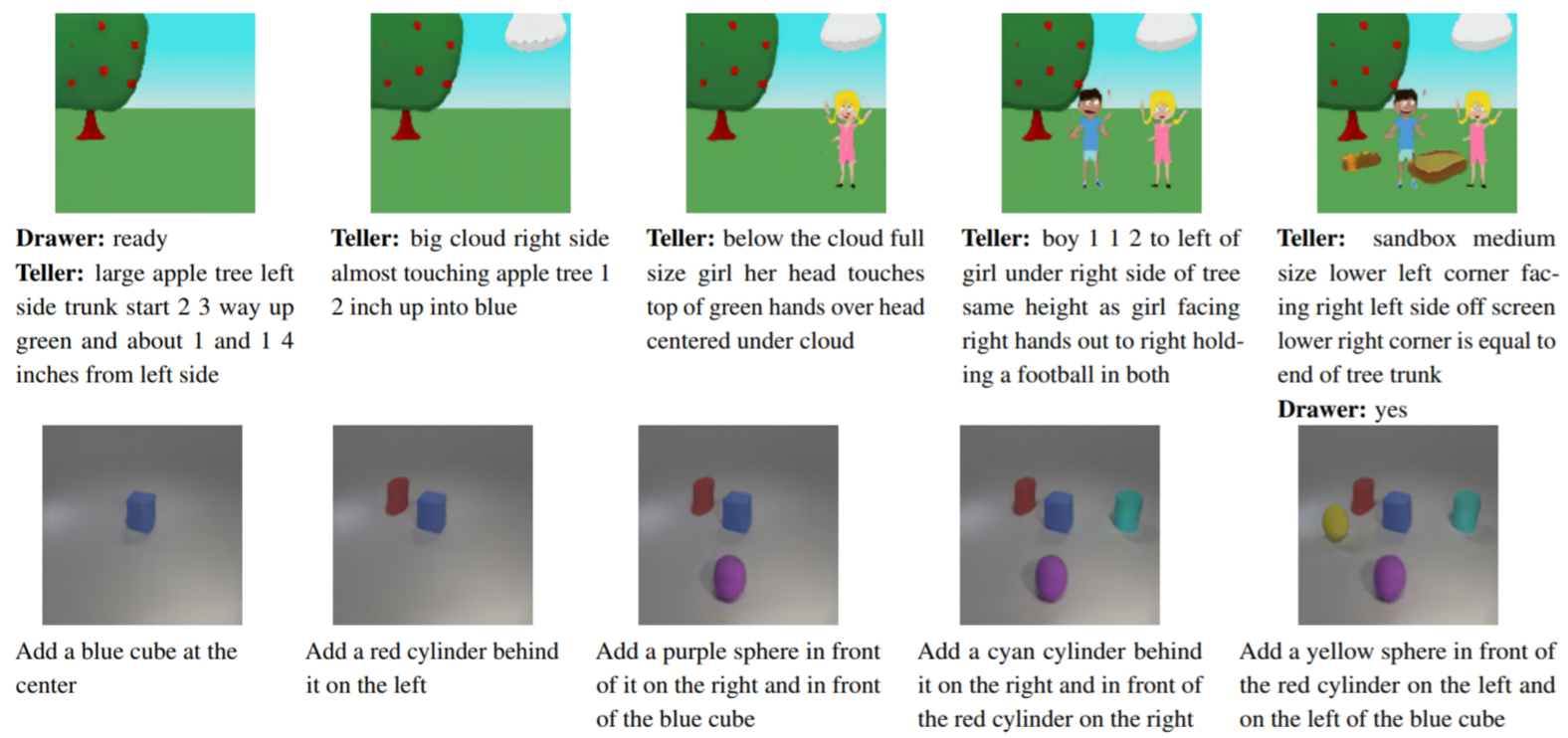
由 GeNeVA-GAN 模型生成的图像,在"叙述者"、"绘制和重复:基于 CoDraw(上排)和 i-CLEVR(下排)数据集上的持续语言指令生成和修改图像",请参阅以下提供的说明:
数据引用:
如果您使用此代码或 GeNeVA 数据集作为任何已发布的研究的一部分,请引用以下文章:
Alaaeldin El-Nouby, Shikhar Sharma, Hannes Schulz, Devon Hjelm, Layla El Asri, Samira Ebrahimi Kahou, Yoshua Bengio, and Graham W. Taylor. "Tell, Draw, and Repeat: Generating and modifying images based on continual linguistic instruction" arXiv preprint arXiv:1811.09845 (2018). @article{elnouby2018tell_draw_repeat, author = {El{-}Nouby, Alaaeldin and Sharma, Shikhar and Schulz, Hannes and Hjelm, Devon and El Asri, Layla and Ebrahimi Kahou, Samira and Bengio, Yoshua and Taylor, Graham W.}, title = {Tell, Draw, and Repeat: Generating and modifying images based on continual linguistic instruction}, journal = , volume = {abs/1811.09845}, year = {2018}, url = {http://arxiv.org/abs/1811.09845}, archivePrefix = , eprint = {1811.09845} }