热门数据集


语料库在线现代汉语字表数据集
Modern Chinese Character List
4044
1.29MB
来自语料库在线的现代汉语语料字表数据集
2019-10-04 (69月前)
免积分下载

语料库在线汉语语料库字词频数据集
Word Frequency Data Set of Modern Chinese Corpus
7745
5.12MB
来自语料库在线的现代汉语语料库字词频数据集
2019-10-04 (69月前)
免积分下载

爱数智慧日语手机朗读数据库
Japanese Read Speech Recognition Corpus
4734
2.4GB
本语料库的录制文本为日常用语。采集方式为手机录音;录音输出为PCM格式。37名来自日本不同区域(如东京、大阪、北海道等)的发言人参与采集。
2019-10-02 (69月前)
免积分下载

CodeSearchNet挑战赛代码数据集
CodeSearchNet Dataset
4863
20GB
CodeSearchNet挑战赛是GitHub和Weights&Biases携手推出的一项新赛事,旨在推动语义代码搜索的相关研究。
2019-10-02 (69月前)
免积分下载

中国高等学校名单数据集
List of National Institutions of Higher Learning
4482
470KB
截至2017年5月31日,全国高等学校共计2914所,其中:普通高等学校2631所(含独立学院265所),成人高等学校283所。数据来源中华人民共和国教育部公开。
2019-10-02 (69月前)
免积分下载

中国各城市车牌前缀信息数据集
Chinese cities license plate prefix information data set
5185
12.43KB
全国各地车牌字母查询表 - 收录了全国各地的车牌字母信息,可以通过查询车牌字母找到是哪个市的车。
2019-10-02 (69月前)
免积分下载

爱尔兰时报新闻标题数据集
IRISH TIMES news title dataset
4576
47MB
1996年-2018年《爱尔兰时报》发布的142万条新闻标题的集合。
2019-09-30 (69月前)
免积分下载

频率最高的9933个最常用汉字数据集
most_frequent_chinese
4761
1MB
数据的收集源于reddit用户areyde的一个简单的问题:“学习所有汉字意味着什么?”可以简化为“您可以为学习汉字制定什么目标?”
2019-09-30 (69月前)
免积分下载

中国工商企业注册信息数据集1千万
Enterprise-Registration-Data-of-Chinese-Mainland
11702
559.4 MB
中国大陆 31 个省份 1978 年至 2019 年一千多万工商企业注册信息,包含企业名称、注册地址、统一社会信用代码、地区、注册日期、经营范围、法人代表、注册资金、企业类型。
2019-09-24 (69月前)
免积分下载

垃圾分类数据集
WASTE CLASSIFICATION
12261
225MB
面对五花八门的生活垃圾,完全搞明白它们的最终归属并不容易,我们可以借助数据的力量,尝试建立分类模型。
2019-09-24 (69月前)
免积分下载
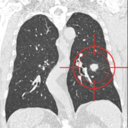
LUNA16肺部CT扫描图片数据集
LUNA16
12171
LUNA16数据集包括888低剂量肺部CT影像(mhd格式)数据,每个影像包含一系列胸腔的多个轴向切片。每个影像包含的切片数量会随着扫描机器、扫描层厚和患者的不同而有差异。
2019-09-24 (69月前)
免积分下载

斯坦福大学Sentiment140情感分析数据集
Sentiment140
8935
77.6MB
Sentiment140数据集是斯坦福大学的一个课堂项目产生的一个用于情感分析的数据集,数据抓取自twitter;这个流行的数据集能让你完美地开启自然语言处理之旅。
2019-09-23 (69月前)
免积分下载